✍️ TLDR: ACE’s self-generated playbooks can grow to 174k tokens, making inference expensive. We explore three retrieval strategies — embedding-based, LLM-based, and Recursive Language Models (RLM) — to compress playbooks into compact sub-playbooks at inference time. Simple retrieval methods (embedding and LLM ranking) preserve 59–65% of the full-adaptation accuracy gain while cutting token usage by over 98%, offering a strong efficiency–accuracy tradeoff. However, more aggressive filtering via RLM backfires on well-curated playbooks: the better the playbook, the more retrieval hurts — suggesting that high-quality playbooks encode subtle, interconnected guidance that top-k selection cannot safely approximate.
[💻 ACE Source Code] [📚 ACE Paper]
Why Retrieval?
ACE (Agentic Context Engineering) works by iteratively refining a playbook — a structured document of tips, strategies, and edge-case guidance — that the agent consults at inference time. This adaptation loop is powerful: on AppWorld, a single epoch of ACE adaptation lifts accuracy from 0.743 to 0.801 by accumulating task-specific knowledge in context. But the playbook that achieves this is large — roughly 174k tokens in its fully adapted form. Every inference call pays the full cost of encoding that context, regardless of whether most of it is relevant to the task at hand.
This raises a natural question: can we retrieve only the most relevant parts of the playbook for each task, preserving most of the accuracy gain while dramatically reducing token cost? If so, retrieval would unlock practical deployment of ACE-adapted agents in settings where long-context inference is expensive or latency-constrained. Below, we evaluate three retrieval approaches — from lightweight embedding similarity to agentic code-based filtering — and find that the answer is nuanced: simple retrieval works surprisingly well, but more aggressive methods can destroy the very structure that makes a good playbook effective.
Embedding-Based Retrieval
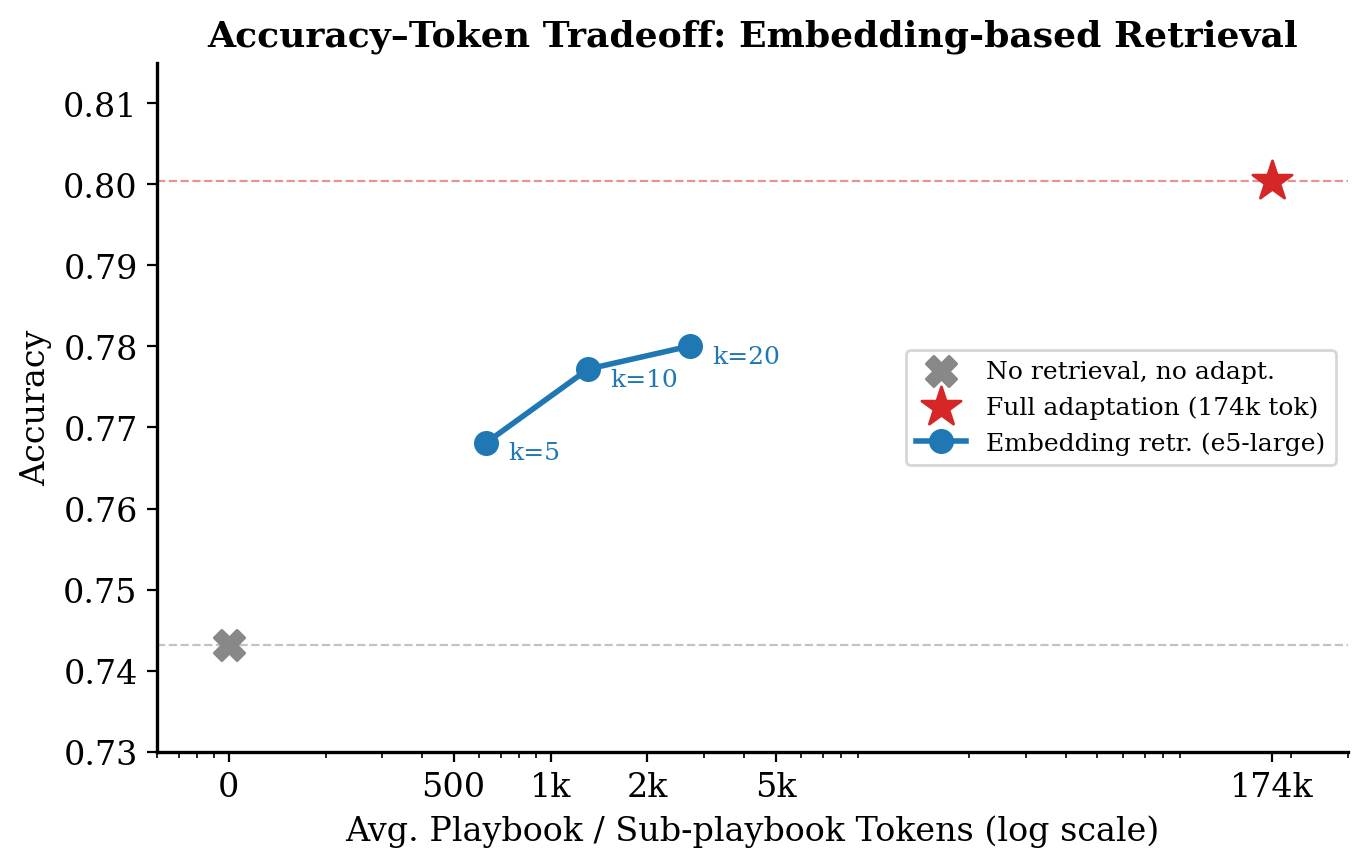
We use the e5-large embedding model as a semantic retriever, evaluated on FiNER — a financial text classification benchmark. We split the full playbook into chunks based on section headings and format each chunk as a single bullet point. All bullets are embedded offline. At runtime, we embed the incoming task instruction with the same model, compute cosine similarity scores, and retrieve the top-k most relevant chunks to form a smaller sub-playbook. Crucially, when assembling the sub-playbook, we preserve each chunk’s original headings and hierarchy so the downstream model still sees the same structural cues as the full playbook — just with far less content.
This approach yields a strong efficiency–accuracy tradeoff. At k=20 (~2.5k tokens), embedding retrieval reaches an accuracy of 0.780 — preserving roughly 59–65% of the accuracy gain from full adaptation (0.801) over the no-adaptation baseline (0.743), while using 98.5–99.6% fewer tokens. Even at k=5 (~700 tokens), accuracy sits at 0.768, already well above the no-adaptation baseline.
Language Model as Retriever
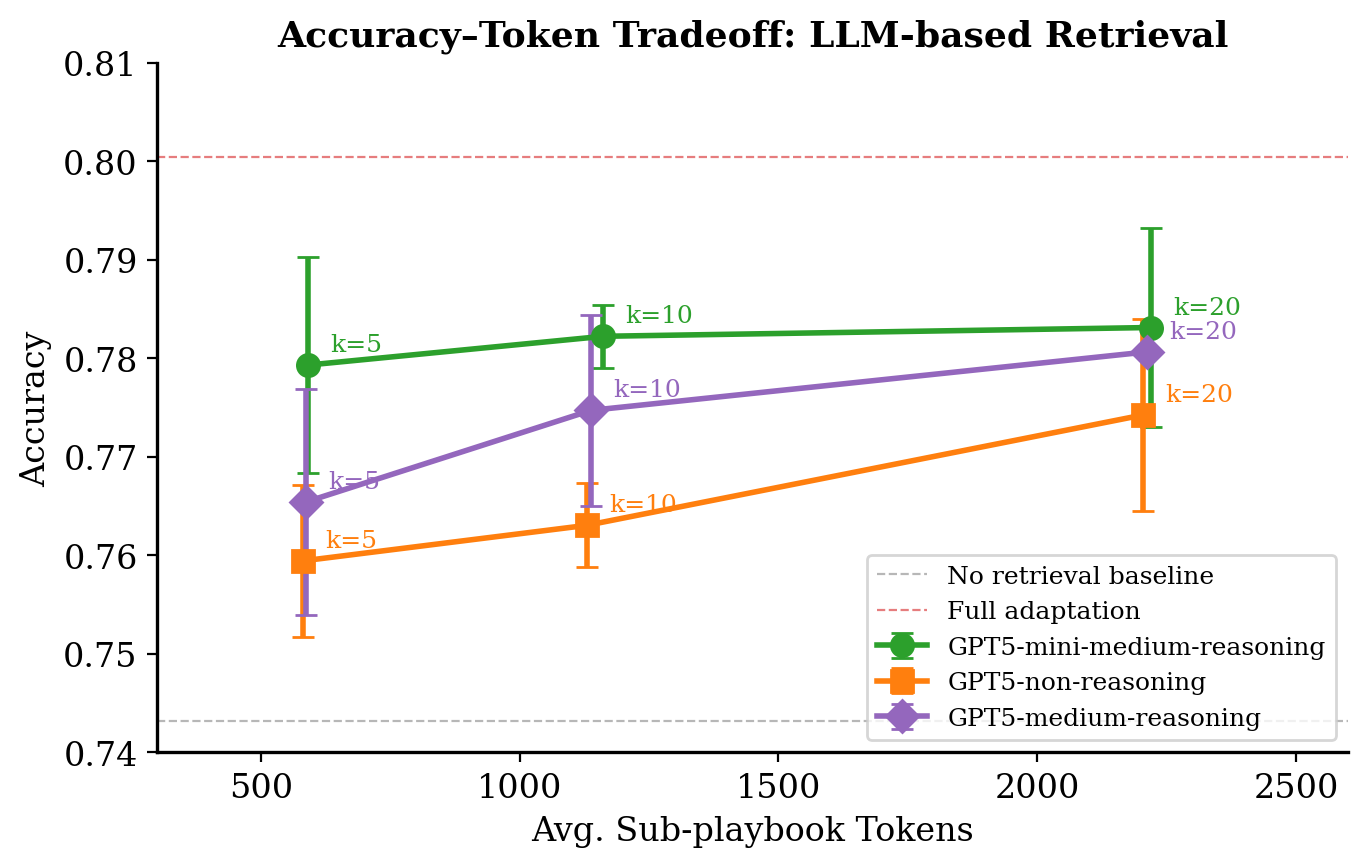
Where embedding retrieval relies on surface-level semantic similarity, LLM-based retrieval treats selection as a ranking problem. Also evaluated on FiNER, we give the LLM the task instruction alongside a list of candidate bullets (each with its original headings preserved) and ask it to select the most relevant ones. The selected top-k bullets are stitched together in their original order, so the resulting sub-playbook retains the full document’s structure.
To stay within context limits while still comparing bullets globally, we use a two-stage process:
- Chunk-level selection: Within smaller, token-bounded chunks, the LLM picks the best bullets.
- Global reranking: Winners from each chunk are compared across the full playbook to produce the final top-k. This design keeps each individual prompt within a fixed token budget while ensuring strong bullets from different parts of the playbook can still compete globally. To account for variance in LLM retrieval, we ran each configuration 3 times and report averaged metrics with error bars.
The results show that LLM retrieval is competitive with embedding retrieval at similar token budgets, and that reasoning improves retrieval quality as k increases. At k=5, differences between reasoning and non-reasoning models are small, but by k=20 (~2.2k tokens), reasoning gives a ~+0.006–0.007 accuracy boost over non-reasoning at the same token cost. Among the models tested, GPT5-mini performs strongest across all k values, suggesting that for this ranking task, a fast and capable small model is sufficient.
Recursive Language Models (RLM)
The first two methods treat retrieval as a single-pass operation: score bullets, take the top-k, done. Recursive Language Models take a fundamentally different approach — and we evaluate them on a fundamentally different benchmark. Where embedding and LLM retrieval were tested on FiNER (text classification), we evaluate RLM retrieval on AppWorld, an agentic benchmark involving multi-step tool use and code generation, where playbooks tend to be larger and more structurally complex.
RLM treats the long prompt as part of an external environment: the playbook is loaded as a variable in a Python REPL, and the LLM writes code to slice, filter, and recursively sub-call itself over chunks. For retrieval, this means the RLM can explore the playbook programmatically — iterating, comparing, and refining its selection — rather than relying on a single embedding lookup or ranking pass. We use RLM to filter the playbook down to the 50 bullets most relevant to each task, then run the downstream agent against that sub-playbook.
Setup
- Playbook 1 — 1-epoch playbook (the default in the ACE open-source repo). Noisier, less curated.
- Playbook 2 — 2-epoch playbook (the best result from the ACE paper). Smaller, more refined.
- The RLM sees only the task instruction and the playbook, and returns the 50 bullets most relevant to that instruction. Retrieval runs independently for each task — variants of the same scenario each get their own top-50.
- All runs are offline evaluations without ground-truth feedback.
- We tested two prompting styles: a prescriptive prompt (v0) with explicit selection rules and a minimal prompt (v1) that lets the model decide freely. Both produce very similar aggregate numbers, so the results below report v0.
Results
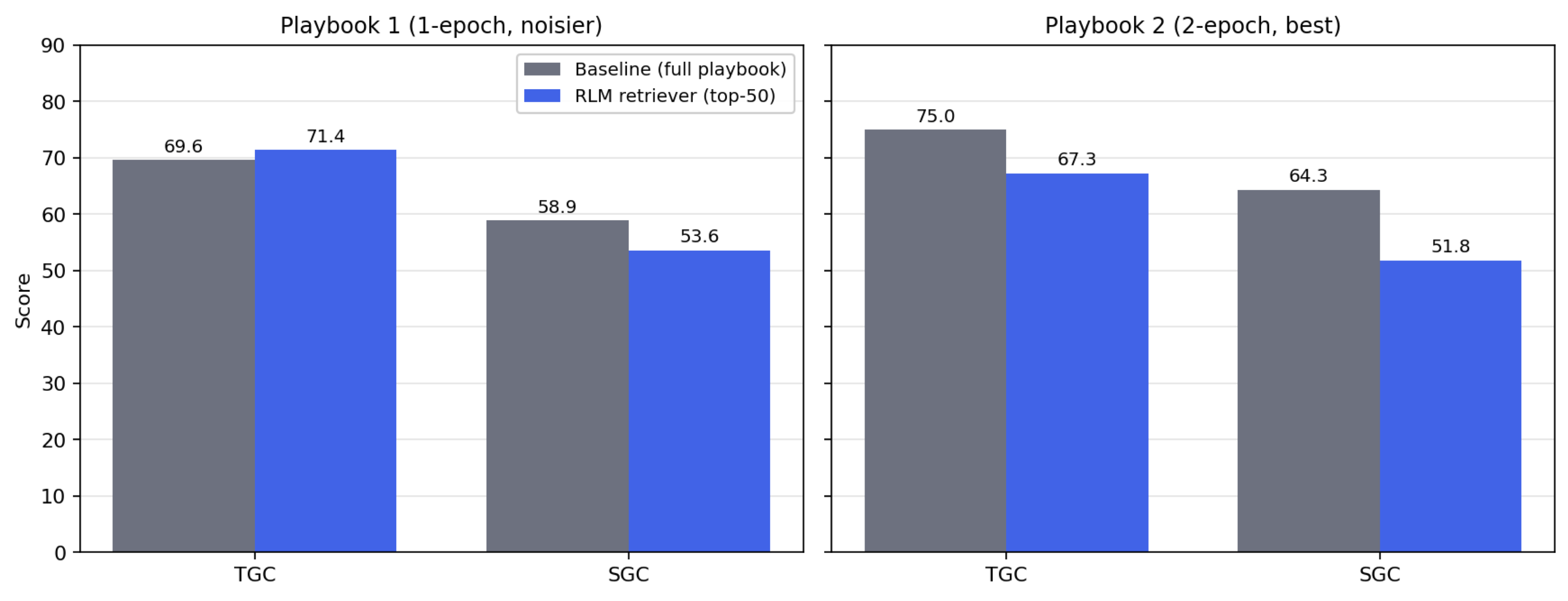
The results are the opposite of what we hoped for. On the noisier 1-epoch playbook, RLM retrieval gives a small TGC bump (+1.8 points) but drops SGC by 5.3 points. On the stronger 2-epoch playbook — the one we actually care about — the retriever hurts both metrics substantially: TGC falls 7.7 points and SGC falls 12.5 points. In other words, the better the playbook, the more damage the retriever does.
By difficulty: where the damage lands
Breaking results down by task difficulty sharpens the picture. On the noisier 1-epoch playbook, RLM retrieval actually helps on the hardest tasks — difficulty-3 TGC jumps from 36.5 to 44.4 (+7.9) — consistent with the intuition that filtering removes distracting bullets when the playbook is noisy. Easy and medium tasks are roughly unchanged.
On the stronger 2-epoch playbook, difficulty-3 is exactly where the retriever fails hardest. TGC on hard tasks collapses from 52.4 to 33.3 (−19.1), and SGC falls from 33.3 to 9.5 (−23.8). Easy tasks also regress (TGC 96.5→93.0, SGC 94.7→84.2), while medium tasks are roughly flat. The well-curated playbook appears to contain exactly the kind of edge-case guidance that hard tasks rely on, and top-50 filtering based on the task instruction alone is not selective enough to keep it.
Why SGC degrades more than TGC
A quick reminder on the metrics: TGC (Task Goal Completion) is the fraction of individual tasks passed, while SGC (Scenario Goal Completion) is stricter — AppWorld groups tasks into scenarios (contrast sets of variants sharing a template but differing in conditions and distractors), and SGC only counts a scenario as solved if every variant passes. SGC is effectively a consistency metric.
This all-or-nothing structure explains why SGC falls faster than TGC. The retriever runs independently on each variant, so any per-task drop in reliability compounds across the variants of a scenario: even a modest chance of dropping a needed bullet on a single variant is enough to fail the whole scenario. Under this kind of multiplicative amplification, a small TGC hit translates into a much larger SGC hit — which is exactly what we observe.
Takeaways
- RLM retrieval is playbook-dependent: slightly helpful on noisy playbooks, clearly harmful on well-optimized ones. For our best playbook, it is a net negative.
- SGC degrades more than TGC. Per-variant retrieval errors compound across a scenario’s variants, and SGC only rewards passing all of them.
- Hard tasks are the high-variance regime. Retrieval helps them on a noisy playbook and destroys them on a curated one — suggesting that edge-case guidance is both the most valuable and the hardest to retrieve.
Looking Ahead
These experiments paint a clear picture: simple retrieval methods offer a strong Pareto tradeoff between accuracy and token cost, preserving the majority of ACE’s adaptation gains at a fraction of the inference budget. But more aggressive, agentic retrieval can backfire — particularly on well-curated playbooks where the structure and completeness of the document matter as much as any individual bullet.
This suggests several directions for future work. First, structure-aware retrieval that respects dependencies between playbook sections (rather than treating bullets as independent) could help avoid the kind of silent information loss that hurts hard tasks. Second, adaptive retrieval budgets — using more bullets for harder or more ambiguous tasks — could help match retrieval depth to task complexity. Finally, the tension between playbook quality and retrievability raises a deeper question: should playbooks be written with retrieval in mind, perhaps with more self-contained, modular entries that degrade gracefully under selection?
For now, if you’re using ACE in a cost-sensitive setting, embedding retrieval at k=10–20 is the practical sweet spot: you get most of the benefit at a tiny fraction of the cost.
ACE (Agentic Context Engineering) was developed by researchers at Stanford University, SambaNova Systems, and UC Berkeley. The paper was accepted at ICLR 2026.